Next-Generation Sequencing (NGS), also known as high-throughput sequencing, is a revolutionary technology used for determining the sequence of DNA or RNA molecules. It has significantly advanced the field of genomics and has numerous applications in various biological and medical fields.
Key Points of Next-Generation Sequencing (NGS):
- Revolutionary Technology: NGS represents a revolutionary advancement in DNA and RNA sequencing, enabling the rapid and cost-effective analysis of genetic material.
- High Throughput: NGS platforms can sequence millions of DNA fragments in parallel, significantly increasing sequencing throughput compared to traditional methods like Sanger sequencing.
- Multiple Applications: NGS has a wide range of applications, including genome sequencing, exome sequencing, RNA sequencing (RNA-Seq), metagenomics, and more.
- Short Read Sequencing: Many NGS platforms produce short reads (usually <1,000 base pairs), making them well-suited for applications like variant calling and gene expression analysis.
- Long Read Sequencing: Some NGS technologies, such as PacBio and Oxford Nanopore, offer long-read sequencing, which is valuable for de novo genome assembly and structural variant detection.
- Bioinformatics Analysis: NGS generates massive amounts of data that require advanced bioinformatics tools for tasks like read alignment, variant calling, and functional annotation.
- Cost-Effective: NGS has made genomic sequencing more affordable, allowing for large-scale projects and making personalized medicine and precision healthcare more feasible.
- Illumina Dominance: Illumina’s sequencing platforms, including the HiSeq and NovaSeq, are among the most widely used NGS systems due to their accuracy, throughput, and established track record.
- Clinical Applications: NGS is increasingly used in clinical settings for genetic testing, cancer diagnosis, and identifying rare genetic disorders.
- Single-Cell Sequencing: NGS can be used to sequence the genomes or transcriptomes of individual cells, enabling insights into cellular heterogeneity and disease mechanisms.
- Epigenomics: NGS is essential for studying epigenetic modifications, such as DNA methylation and histone modifications, which play crucial roles in gene regulation.
- Metagenomics: NGS is used to analyze complex microbial communities, such as those in the human gut or environmental samples, to understand their composition and function.
- RNA-Seq: RNA-Seq allows for the quantification of gene expression levels, splice variants, and non-coding RNA species, enhancing our understanding of gene regulation.
- Phylogenomics: NGS is used in phylogenetic studies to understand evolutionary relationships by comparing genetic sequences across species.
- ChIP-Seq: Chromatin Immunoprecipitation followed by sequencing (ChIP-Seq) is used to identify DNA-binding sites for specific proteins, such as transcription factors and histones.
- Personalized Medicine: NGS enables the identification of genetic variants that can inform personalized treatment plans for patients with genetic diseases or cancer.
- Drug Discovery: NGS is employed in drug development to identify potential drug targets, assess drug efficacy, and predict patient responses.
- Technological Advancements: NGS technologies continue to evolve, with innovations like long-read sequencing and portable sequencers, expanding the range of possible applications.
Defination of Next-Generation Sequencing (NGS):
Next-Generation Sequencing (NGS) is a high-throughput DNA and RNA sequencing technology that allows for the rapid and cost-effective determination of nucleotide sequences in genetic material.
Classification of Generations :
- First Generation Sequencing: This refers to the early methods of DNA sequencing, primarily the Sanger sequencing method, which was developed in the 1970s. It was a groundbreaking technique but was relatively slow and expensive compared to NGS.
- Second Generation Sequencing (NGS): NGS technologies, which emerged around the mid-2000s, marked a significant advancement over Sanger sequencing. These include platforms like Illumina, Ion Torrent, and others. They brought about high-throughput, parallel sequencing, making it faster and more cost-effective.
- Third Generation Sequencing: Third-generation sequencing technologies represent another leap in sequencing capabilities. These include technologies like PacBio (Pacific Biosciences) and Oxford Nanopore Technologies. They offer long-read sequencing capabilities, which can be advantageous for certain applications, such as de novo genome assembly and detecting structural variations.
- Fourth Generation Sequencing (Potential Future): While not yet fully realized, the term “fourth generation sequencing” may be used to describe future sequencing technologies that could overcome current limitations and offer even more accuracy, speed, and versatility.
Historical Context:
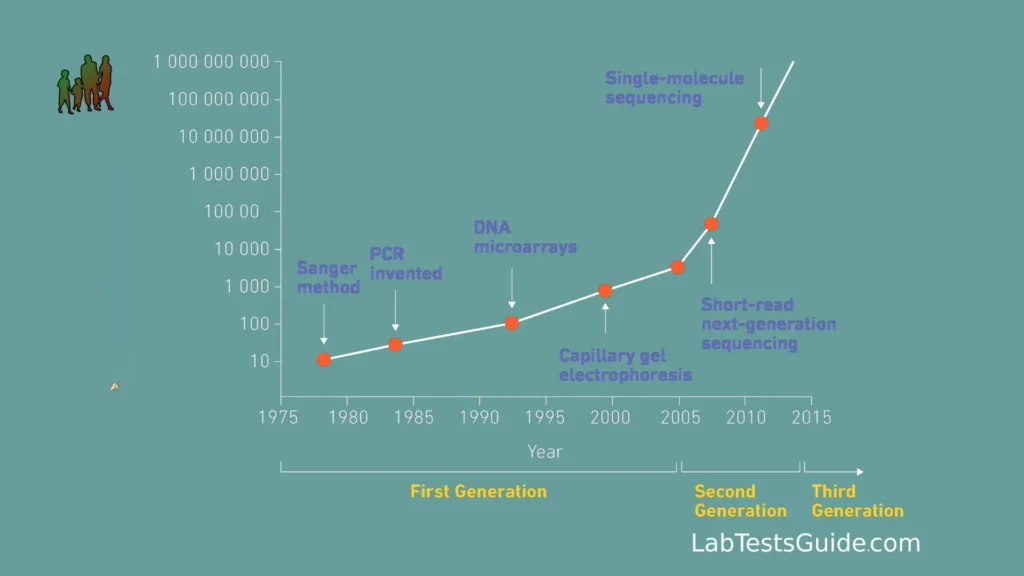
- Sanger Sequencing Era (1970s-2000s): Before the advent of NGS, the primary method for DNA sequencing was Sanger sequencing, developed by Frederick Sanger in the late 1970s. While groundbreaking, Sanger sequencing was relatively slow, labor-intensive, and expensive.
- Human Genome Project (1990-2003): The Human Genome Project (HGP) was a major international effort to map and sequence the entire human genome. It served as a driving force for advancements in sequencing technology and inspired the development of faster and more cost-effective methods.
- Emergence of NGS (Mid-2000s): The term “Next-Generation Sequencing” began to be used in the mid-2000s to describe a new generation of sequencing technologies that offered high-throughput capabilities. The first commercial NGS platform, 454 Life Sciences’ GS 20, was introduced in 2005.
- Key Milestones:
- Illumina: Illumina’s Genome Analyzer, released in 2006, played a pivotal role in the NGS revolution. It offered high accuracy, scalability, and reduced per-base sequencing costs.
- Other Platforms: Other NGS platforms, such as Roche 454, SOLiD (Applied Biosystems), and Helicos, also emerged during this time, each with its unique sequencing chemistry and characteristics.
- NGS Advancements: NGS technologies quickly evolved, leading to increased read lengths, enhanced accuracy, and improved sample preparation methods. This made NGS more accessible to researchers and clinicians.
- Rapid Genome Sequencing: NGS made it possible to sequence entire genomes quickly and cost-effectively. This led to groundbreaking discoveries in genomics, including the identification of genetic variations associated with diseases and the study of diverse species.
- Clinical Applications: NGS has found applications in clinical diagnostics, personalized medicine, and cancer genomics, allowing for the identification of disease-causing mutations and guiding treatment decisions.
- Research and Beyond: Beyond genomics, NGS has been applied to study epigenetics, metagenomics, transcriptomics, and more, contributing to a deeper understanding of biology and disease.
- Continued Innovation: NGS technologies continue to evolve with innovations in long-read sequencing (e.g., PacBio and Oxford Nanopore), single-cell sequencing, and portable sequencing devices, expanding the range of applications.
Purpose of Next-Generation Sequencing (NGS):
- Genome Sequencing: Purpose: To determine the complete DNA sequence of an organism’s genome for research, diagnostics, and evolutionary studies.
- Exome Sequencing: Purpose: To focus on the protein-coding regions of the genome (exons) for identifying genetic variants associated with diseases.
- RNA Sequencing (RNA-Seq): Purpose: To analyze gene expression levels, splice variants, and non-coding RNAs to understand gene regulation and transcriptomics.
- Metagenomics: Purpose: To study complex microbial communities in environmental, clinical, and agricultural samples to identify and characterize microorganisms.
- Epigenomics: Purpose: To investigate epigenetic modifications such as DNA methylation and histone modifications to understand gene regulation and epigenetic inheritance.
- Cancer Genomics: Purpose: To identify genetic mutations and genomic alterations in cancer cells to inform diagnosis, prognosis, and treatment decisions.
- Population Genetics: Purpose: To study genetic variation within and between populations to understand evolutionary processes, migration patterns, and genetic diversity.
- Clinical Diagnostics: Purpose: To identify disease-causing mutations, assess disease risk, and guide treatment decisions in personalized medicine.
- Functional Genomics: Purpose: To investigate the function of genes and non-coding regions through techniques like CRISPR screens and ChIP-Seq.
- Structural Genomics: Purpose: To study genomic structural variations, including insertions, deletions, duplications, and rearrangements, to understand their role in diseases.
- Comparative Genomics: Purpose: To compare the genomes of different species to understand evolutionary relationships, gene conservation, and adaptations.
- Single-Cell Sequencing: Purpose: To analyze individual cells’ genomes, transcriptomes, and epigenomes, enabling insights into cellular heterogeneity and development.
- Forensic Genetics: Purpose: To identify individuals, establish paternity, and solve crimes by analyzing DNA evidence.
- Environmental Genomics: Purpose: To study the genetic diversity and functional potential of microorganisms in environmental samples, such as soil and water.
- Drug Discovery: Purpose: To identify drug targets, screen for potential therapeutic compounds, and understand drug resistance mechanisms.
- Agricultural Genomics: Purpose: To improve crop yields, develop disease-resistant strains, and enhance agricultural practices through genetic analysis.
- Infectious Disease Genomics: Purpose: To study the genetic diversity of pathogens, track disease outbreaks, and identify drug resistance mutations.
- Rare Disease Diagnosis: Purpose: To diagnose rare genetic disorders by identifying disease-causing mutations in affected individuals.
- Pharmacogenomics: Purpose: To personalize drug treatments based on an individual’s genetic makeup to maximize drug efficacy and minimize side effects.
- Evolutionary Genomics: Purpose: To investigate the genetic basis of evolutionary adaptations, speciation events, and the emergence of new traits.
Sequencing Platforms:
Next-Generation Sequencing (NGS) encompasses a variety of sequencing platforms, each with its own technologies and characteristics. Here is a list of some prominent NGS sequencing platforms:
- Illumina Sequencing:
- Principle: Sequencing by synthesis using reversible terminators.
- Key Features: High accuracy, short read lengths, high throughput, and cost-effective.
- Applications: Whole genome sequencing, exome sequencing, RNA-Seq, and more.
- Ion Torrent Sequencing:
- Principle: Detection of hydrogen ions released during DNA synthesis.
- Key Features: Speed, suitability for targeted sequencing, and benchtop instruments.
- Applications: Targeted sequencing, including cancer panels and amplicon sequencing.
- PacBio Sequencing (SMRT Sequencing):
- Principle: Real-time observation of DNA polymerase during synthesis.
- Key Features: Long read lengths, capability to capture structural variations.
- Applications: De novo genome assembly, full-length RNA sequencing, and epigenetics studies.
- Oxford Nanopore Sequencing:
- Principle: Detection of changes in electrical current as DNA passes through nanopores.
- Key Features: Extremely long read lengths, portable sequencers.
- Applications: Genome sequencing, metagenomics, real-time pathogen detection.
- 454 Pyrosequencing (Roche 454 Sequencing):
- Principle: Detection of light emitted during nucleotide incorporation.
- Key Features: Longer read lengths compared to Illumina.
- Applications: De novo genome sequencing, amplicon sequencing.
- SOLID Sequencing (Sequencing by Oligonucleotide Ligation and Detection):
- Principle: Ligation-based sequencing with fluorescently labeled probes.
- Key Features: High accuracy, suitable for SNP detection.
- Applications: Whole exome sequencing, ChIP-Seq.
- Helicos Sequencing (Single-Molecule Sequencing):
- Principle: Serial imaging of fluorescently labeled nucleotides during synthesis.
- Key Features: Single-molecule sequencing, no amplification bias.
- Applications: Gene expression analysis, RNA-Seq.
- Complete Genomics Sequencing:
- Principle: Direct sequencing of DNA nanoarrays.
- Key Features: No need for library preparation, cost-effective for large projects.
- Applications: Genome sequencing for population studies.
- BGISEQ Sequencing:
- Principle: DNBSEQ technology using combinatorial probe-anchor synthesis.
- Key Features: High throughput, relatively low cost.
- Applications: Genome sequencing, transcriptome analysis.
- Nanopore Arrays (Emerging Technology):
- Principle: Nanopore-based sequencing with improved accuracy and throughput (under development).
Application of Next-Generation Sequencing (NGS):
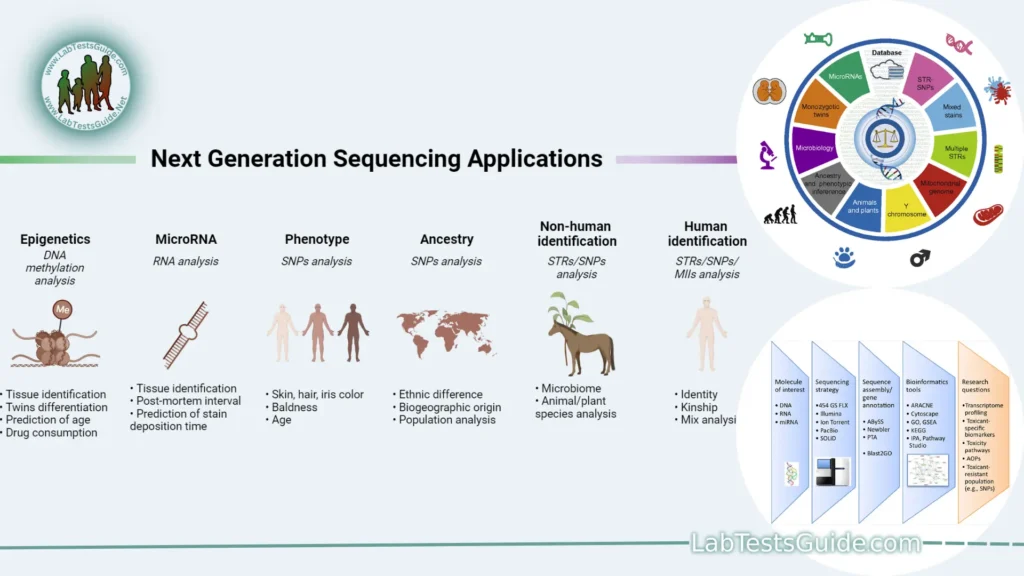
- Genome Sequencing:
- Purpose: Determining the complete DNA sequence of an organism’s genome.
- Applications: Studying genetic variations, identifying disease-related genes, and understanding evolutionary relationships.
- Exome Sequencing:
- Purpose: Focusing on protein-coding regions (exons) of the genome to identify disease-causing mutations.
- Applications: Diagnosing genetic disorders, discovering novel disease genes, and researching Mendelian diseases.
- RNA Sequencing (RNA-Seq):
- Purpose: Analyzing gene expression, splicing patterns, and non-coding RNAs.
- Applications: Studying gene regulation, identifying novel transcripts, and biomarker discovery.
- Metagenomics:
- Purpose: Analyzing genetic material from complex microbial communities.
- Applications: Characterizing microbiomes, studying environmental samples, and identifying novel species.
- Epigenomics:
- Purpose: Investigating epigenetic modifications, such as DNA methylation and histone modifications.
- Applications: Understanding gene regulation, studying epigenetic changes in diseases, and exploring developmental processes.
- Cancer Genomics:
- Purpose: Identifying genetic mutations and genomic alterations in cancer cells.
- Applications: Personalizing cancer treatments, detecting drug resistance mutations, and understanding cancer evolution.
- Population Genetics:
- Purpose: Analyzing genetic variation within and between populations.
- Applications: Investigating evolutionary processes, migration patterns, and genetic diversity.
- Clinical Diagnostics:
- Purpose: Identifying disease-causing mutations, assessing disease risk, and guiding personalized medicine.
- Applications: Diagnosing rare genetic disorders, predicting treatment responses, and genetic counseling.
- Functional Genomics:
- Purpose: Investigating gene function and interactions.
- Applications: Functional annotation of genomes, studying gene networks, and functional screens.
- Structural Genomics:
- Purpose: Identifying structural variations, including insertions, deletions, and rearrangements.
- Applications: Understanding disease mechanisms, diagnosing genetic disorders, and characterizing genome architecture.
- Comparative Genomics:
- Purpose: Comparing genomes of different species to study evolutionary relationships.
- Applications: Understanding evolutionary adaptations, gene conservation, and speciation events.
- Single-Cell Sequencing:
- Purpose: Analyzing genomes, transcriptomes, and epigenomes of individual cells.
- Applications: Exploring cellular heterogeneity, developmental biology, and disease mechanisms.
- Forensic Genetics:
- Purpose: Identifying individuals, establishing parentage, and solving crimes using DNA evidence.
- Applications: Criminal investigations, disaster victim identification, and missing persons cases.
- Environmental Genomics:
- Purpose: Studying genetic diversity and functional potential of microorganisms in environmental samples.
- Applications: Soil and water quality assessment, bioremediation studies, and ecological research.
- Drug Discovery:
- Purpose: Identifying drug targets, screening for potential therapeutics, and studying drug resistance mechanisms.
- Applications: Accelerating drug development, optimizing treatments, and personalized medicine.
- Agricultural Genomics:
- Purpose: Improving crop yields, developing disease-resistant strains, and enhancing agricultural practices.
- Applications: Crop breeding, disease resistance studies, and crop trait modification.
- Infectious Disease Genomics:
- Purpose: Studying genetic diversity of pathogens, tracking disease outbreaks, and identifying drug resistance mutations.
- Applications: Epidemiological studies, vaccine development, and antimicrobial resistance monitoring.
- Rare Disease Diagnosis:
- Purpose: Diagnosing rare genetic disorders by identifying disease-causing mutations.
- Applications: Providing accurate diagnoses, guiding treatment decisions, and supporting affected individuals.
- Pharmacogenomics:
- Purpose: Personalizing drug treatments based on individual genetic variations.
- Applications: Optimizing drug efficacy, minimizing side effects, and improving patient outcomes.
- Evolutionary Genomics:
- Purpose: Investigating the genetic basis of evolutionary adaptations, speciation events, and the emergence of new traits.
- Applications: Understanding evolutionary processes, conservation biology, and biodiversity studies.
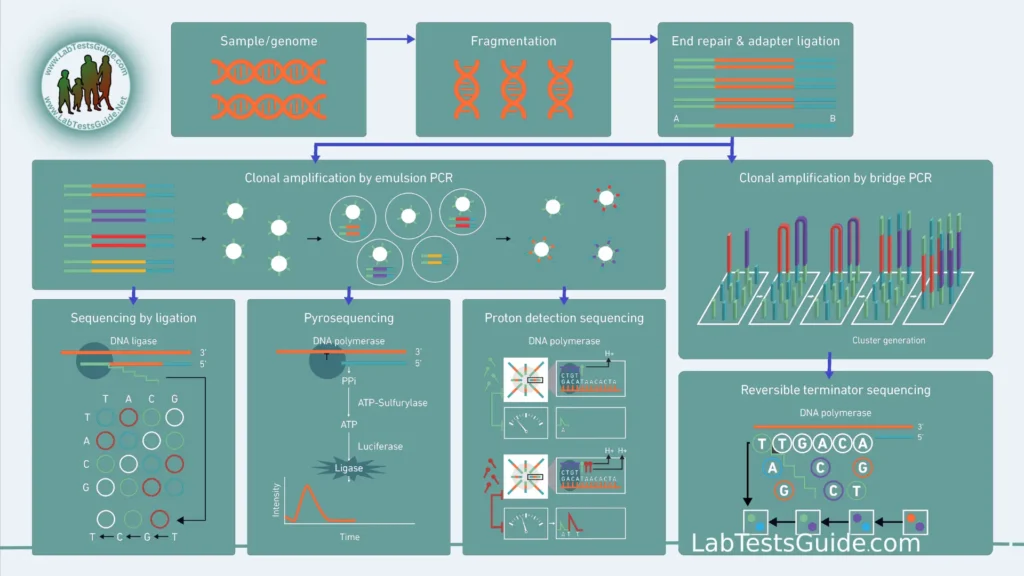
Principles of NGS:
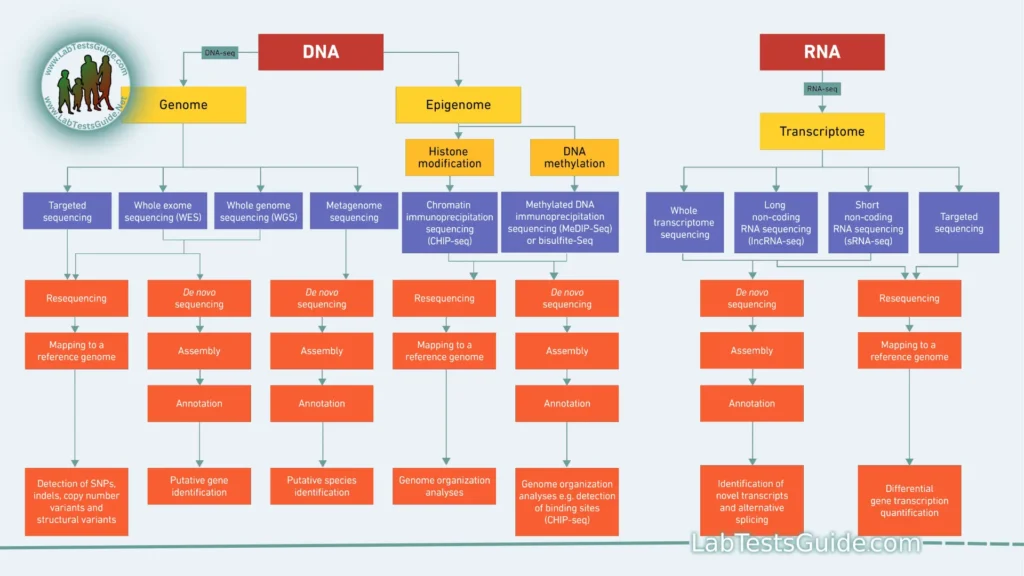
Next-Generation Sequencing (NGS) encompasses several sequencing platforms, each with its unique principles and methods. However, there are common principles that underlie the technology. Here are the key principles of NGS:
- Parallel Sequencing: NGS achieves high throughput by simultaneously sequencing millions of DNA fragments in parallel. This is in contrast to Sanger sequencing, which sequences one fragment at a time.
- Fragmentation: The DNA or RNA sample is fragmented into smaller pieces, typically several hundred base pairs long. These fragments serve as templates for sequencing.
- Library Preparation: Adapters are ligated to the fragmented DNA or RNA molecules. These adapters contain sequences necessary for amplification, attachment to sequencing surfaces, and sequencing chemistry.
- Amplification: In some NGS platforms, such as Illumina, PCR amplification is used to create clonal clusters of identical DNA molecules on a flow cell surface. Each cluster represents one original DNA fragment.
- Sequencing by Synthesis (SBS): Most NGS platforms employ the SBS method. During SBS, individual nucleotides (A, C, G, T) are added to the growing DNA strand one at a time. As each nucleotide is incorporated, a fluorescent signal is emitted, allowing the determination of the sequence.
- Detection: Fluorescent signals generated during sequencing are detected by specialized cameras or sensors. The color and intensity of the signals correspond to the incorporated nucleotide.
- Base Calling: Software algorithms interpret the fluorescent signals and convert them into nucleotide base calls, generating a sequence read for each cluster.
- Data Output: NGS platforms produce vast amounts of sequence data in the form of short reads (or long reads in some cases), typically stored as FASTQ files.
- Bioinformatics Analysis: After data generation, bioinformatics tools are used for read alignment, variant calling, quality control, and downstream analyses. This step is critical for extracting meaningful biological insights from NGS data.
- Quality Control: NGS data undergo quality control processes to assess the reliability and accuracy of sequencing results. This includes checking for sequence errors, read depth, and coverage uniformity.
- Data Integration: NGS data can be integrated with other omics data (e.g., proteomics, metabolomics) to provide a comprehensive view of biological processes.
- Data Interpretation: Researchers and clinicians interpret NGS data to gain insights into genetics, genomics, gene expression, epigenetics, and more. This can inform biological research, diagnostics, and personalized medicine.
- Applications: NGS is applied to various fields, including genomics, transcriptomics, epigenomics, metagenomics, and more, enabling a wide range of biological studies and clinical applications.
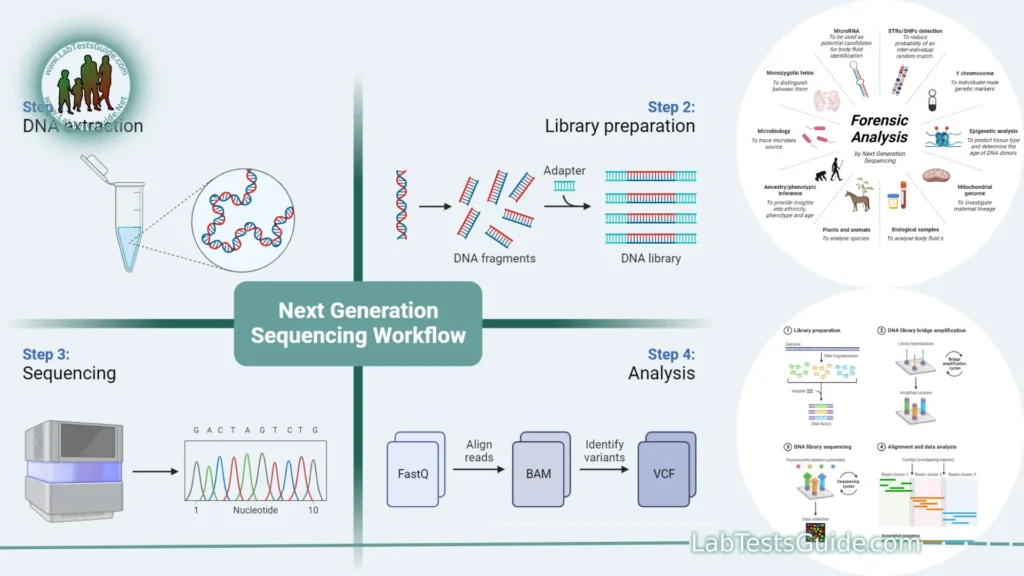
Next-Generation Sequencing workflow:
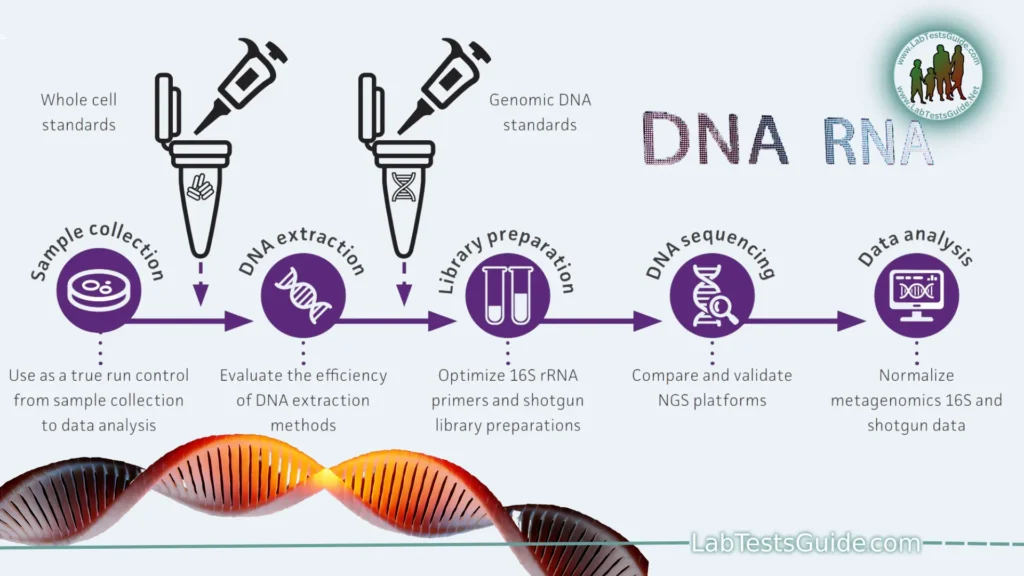
- Sample Preparation:
- DNA/RNA Extraction: The process begins with the isolation of high-quality DNA or RNA from the sample of interest (e.g., cells, tissues, blood).
- Quality Control: The extracted genetic material is assessed for quantity and purity using techniques like spectrophotometry or fluorometry.
- Library Preparation:
- Fragmentation: The DNA or RNA is fragmented into smaller pieces, typically ranging from a few hundred to a few thousand base pairs.
- Adaptor Ligation: Short DNA or RNA adapters with specific sequences are ligated to the fragmented molecules. These adapters serve as primers for amplification and sequencing.
- Size Selection: If needed, size selection is performed to remove unwanted fragments and retain the desired fragment lengths.
- Library Amplification: PCR or other amplification methods are used to create multiple copies of the library molecules. This step is critical for generating enough material for sequencing.
- Clustering (Optional, depending on the NGS platform):
- In some NGS platforms (e.g., Illumina), library molecules are immobilized and amplified on a solid surface, creating clonal clusters of identical DNA fragments. Each cluster represents one original DNA fragment.
- Sequencing:
- Sequencing Chemistry: Depending on the NGS platform, sequencing chemistry varies. The most common method is Sequencing by Synthesis (SBS), where nucleotide bases (A, C, G, T) are added one at a time, and emitted fluorescence signals are detected to determine the sequence.
- Data Generation: As each nucleotide is incorporated, fluorescent signals are recorded, generating sequence reads. The sequences are typically generated in parallel for millions of clusters.
- Data Analysis:
- Base Calling: Software processes the raw data to call nucleotide bases and generate sequence reads.
- Quality Control: Quality control metrics are applied to assess the accuracy and reliability of the sequencing data.
- Read Alignment: Sequence reads are aligned or mapped to a reference genome or transcriptome to determine their genomic or transcriptomic locations.
- Variant Calling: Variants, such as single nucleotide polymorphisms (SNPs) and insertions/deletions (indels), are identified by comparing the sequenced DNA to a reference sequence.
- Bioinformatics Analysis: Various bioinformatics tools and pipelines are used for downstream analysis, including gene expression quantification, pathway analysis, and functional annotation.
- Data Interpretation:
- Researchers and clinicians interpret the NGS data to gain insights into genetic variations, gene expression patterns, epigenetic modifications, and more.
- Findings are related to specific research questions, such as understanding disease mechanisms, identifying therapeutic targets, or diagnosing genetic disorders.
- Reporting and Visualization:
- Results are compiled into reports and visualizations for publication, clinical diagnosis, or further research.
- Follow-Up Experiments (Optional):
- Depending on the study’s objectives, additional experiments, such as validation studies or functional assays, may be conducted to confirm NGS findings.
Bioinformatics in NGS:
Bioinformatics plays a critical role in Next-Generation Sequencing (NGS) by handling the massive amounts of data generated and extracting meaningful biological insights from sequencing experiments. Here’s how bioinformatics is applied in NGS:
- Data Preprocessing:
- Quality Control: Bioinformatics tools assess the quality of sequencing data by checking for base call accuracy, sequence read length distribution, and other quality metrics.
- Adapter Trimming: Sequencing adapters, which are added during library preparation, are removed to ensure accurate downstream analysis.
- Read Filtering: Low-quality reads, duplicate reads, and contaminating reads are filtered out to improve data quality.
- Sequence Alignment:
- Reference Alignment: Sequence reads are aligned or mapped to a reference genome or transcriptome. Bioinformatics algorithms ensure that each read is correctly positioned on the reference, allowing researchers to identify genomic or transcriptomic locations.
- Variant Calling:
- Single Nucleotide Polymorphisms (SNPs) and Indels: Bioinformatics tools identify genetic variations, such as SNPs and indels, by comparing the sequenced DNA to the reference genome. Variant calling algorithms assess the likelihood of each variant.
- Structural Variations: Detection of larger structural variations, such as insertions, deletions, duplications, and translocations, is performed using specialized bioinformatics tools.
- Gene Expression Analysis (RNA-Seq):
- Quantification: Bioinformatics tools quantify gene expression levels, isoform usage, and transcript abundances from RNA-Seq data.
- Differential Expression: Researchers identify genes that are differentially expressed between experimental conditions (e.g., diseased vs. healthy samples) to understand regulatory mechanisms and disease pathways.
- Functional Annotation:
- Bioinformatics tools annotate sequenced genes and variants to provide functional context, including gene ontology, pathway analysis, and identification of protein domains and motifs.
- Epigenomics Analysis:
- Bioinformatics methods are used to analyze DNA methylation, histone modifications, and chromatin accessibility data, providing insights into epigenetic regulation.
- Metagenomics:
- Bioinformatics tools analyze metagenomic data to identify and characterize microorganisms in complex microbial communities, assess microbial diversity, and study their functional potential.
- Visualization:
- Data visualization tools and software generate plots, heatmaps, and graphs to help researchers and clinicians interpret and communicate their findings effectively.
- Integration with Other Omics Data:
- Bioinformatics facilitates the integration of NGS data with other omics data, such as proteomics and metabolomics, to provide a more comprehensive understanding of biological systems.
- Software and Pipelines:
- Bioinformatics pipelines, often implemented in software packages (e.g., BWA, GATK, STAR), automate data analysis workflows and ensure reproducibility.
- Custom Analysis:
- Depending on the specific research question, bioinformaticians may develop custom scripts and algorithms to address unique analytical challenges.
- Data Sharing and Databases:
- Bioinformatics resources, databases, and data repositories (e.g., NCBI, ENCODE, GenBank) store and provide access to NGS data for the research community.
What are Genetic Variants:

- Single Nucleotide Polymorphisms (SNPs): SNPs are single base pair changes in the DNA sequence, representing the most common type of genetic variation in the human genome. They can occur at specific positions in the genome and are associated with diverse traits and diseases.
- Insertions and Deletions (Indels): Indels involve the insertion or deletion of one or more nucleotides in the DNA sequence, leading to length variations at specific genomic locations.
- Copy Number Variations (CNVs): CNVs are structural variations characterized by changes in the number of copies of a DNA segment. They can include gene duplications, deletions, and complex rearrangements.
- Tandem Repeat Variations: These variations consist of short DNA sequences repeated consecutively within a genomic region. The number of repeats can vary among individuals and impact gene expression and phenotypic traits.
- Structural Variants (SVs): SVs are larger-scale variations involving the rearrangement, duplication, or deletion of significant DNA segments. They encompass translocations, inversions, and large insertions or deletions.
- Point Mutations: Point mutations are changes in a single nucleotide, which can be transitions (substitution of a purine with another purine or a pyrimidine with another pyrimidine) or transversions (substitution of a purine with a pyrimidine or vice versa).
- Frameshift Mutations: Frameshift mutations occur when nucleotides are inserted or deleted from a DNA sequence in a way that shifts the reading frame during translation, potentially resulting in non-functional proteins.
- Missense Mutations: Missense mutations are point mutations that change a single nucleotide, leading to the substitution of one amino acid for another in the encoded protein. They can affect protein structure and function.
- Nonsense Mutations: Nonsense mutations are point mutations that create premature stop codons in the coding sequence, resulting in truncated and often non-functional proteins.
- Silent Mutations: Silent mutations are point mutations that do not change the amino acid sequence of the encoded protein due to the redundancy of the genetic code. They typically have no discernible phenotypic effect.
- Splice Site Mutations: Splice site mutations affect the conserved sequences at exon-intron junctions, leading to altered mRNA splicing and potentially non-functional or dysfunctional protein products.
- Intronic Variants: Variants located within introns (non-coding regions) of genes can influence gene expression and regulation by affecting splicing, transcription, or other regulatory elements.
Limitations of NGS:
- Read Length: NGS platforms typically produce short sequence reads, which can make it challenging to assemble genomes with repetitive regions or analyze long-range structural variations.
- Error Rates: NGS can have error rates, particularly in homopolymer regions (repeating nucleotides), which can affect variant calling accuracy and data quality.
- Coverage Uniformity: NGS may exhibit uneven coverage across the genome, leading to gaps or regions with low sequencing depth, which can affect variant detection and downstream analysis.
- Complex Structural Variations: Complex structural variations, such as chromosomal rearrangements and inversions, may be challenging to detect accurately using standard NGS approaches.
- Repetitive Regions: Highly repetitive genomic regions can be difficult to sequence and assemble, leading to incomplete or inaccurate results.
- GC Bias: NGS can exhibit GC content bias, resulting in varying sequencing depths for regions with different GC content, potentially impacting data analysis.
- Sequence Errors: Sequencing errors, including substitutions, insertions, and deletions, can occur and require advanced error correction methods.
- Library Preparation Artifacts: Artifacts introduced during library preparation, such as PCR duplicates, can lead to data redundancy and affect variant calling and quantification.
- High Computational Demands: NGS data analysis demands significant computational resources and expertise, which can be a limitation for some research settings.
- Data Storage and Management: Managing and storing large volumes of NGS data can be challenging and costly, particularly for long-term storage and data sharing.
- Sample Contamination: Contamination of samples during handling or library preparation can lead to incorrect results and necessitate rigorous quality control measures.
- Ethical and Privacy Concerns: The generation of extensive genetic data raises ethical and privacy concerns, requiring careful data handling and consent procedures.
- Turnaround Time: NGS workflows can have longer turnaround times compared to other diagnostic methods, impacting clinical applications where rapid results are needed.
- Limited Detection of Epigenetic Modifications: Standard NGS techniques may not provide comprehensive information about epigenetic modifications, necessitating additional assays for detailed epigenomic studies.
- Cost: While NGS costs have decreased over the years, it can still be expensive, particularly for large-scale projects or clinical applications.
Advantages and DisAdvantages:
Advantages of NGS:
- High Throughput: NGS platforms can generate vast amounts of sequencing data, allowing researchers to analyze multiple samples simultaneously.
- Speed: NGS is significantly faster than traditional Sanger sequencing, enabling quicker results for research and clinical applications.
- Cost-Effective: The per-base cost of sequencing has decreased over the years, making NGS more accessible for various research projects and clinical diagnostics.
- Whole Genome Sequencing: NGS allows for whole genome sequencing, providing a comprehensive view of an individual’s genetic makeup and potential disease risk factors.
- Customization: NGS can be tailored to specific research questions, enabling targeted sequencing of regions of interest or whole genome/exome sequencing as needed.
- Detection of Various Variants: NGS can identify a wide range of genetic variants, including SNPs, indels, CNVs, and structural variations, enhancing its versatility.
- Applications Across Disciplines: NGS is widely used in genomics, transcriptomics, epigenomics, metagenomics, and more, enabling diverse scientific investigations.
- Personalized Medicine: NGS is crucial in the field of personalized medicine, where genetic information informs treatment decisions and drug selection.
- Rare Disease Diagnosis: NGS can help diagnose rare genetic disorders by identifying disease-causing mutations in affected individuals.
- Research Advancements: NGS has led to significant advances in genetics, genomics, and our understanding of complex diseases and traits.
Disadvantages of NGS:
- Data Complexity: NGS generates massive volumes of data that require advanced computational and bioinformatics resources for processing and analysis.
- Short Read Lengths: Most NGS platforms produce short reads, which can be challenging for de novo genome assembly and analyzing repetitive regions.
- Data Storage: Storing and managing large NGS datasets can be costly and require robust infrastructure.
- Quality Control: Ensuring data quality is critical, as sequencing errors, artifacts, and biases can impact the accuracy of results.
- Bioinformatics Expertise: NGS data analysis requires specialized bioinformatics expertise, which may not be readily available to all researchers.
- GC Bias: NGS can exhibit bias in sequencing GC-rich or GC-poor regions, affecting coverage uniformity.
- Ethical and Privacy Concerns: The generation of extensive genetic data raises ethical and privacy concerns, necessitating careful data handling and consent procedures.
- Turnaround Time: NGS workflows can have longer turnaround times compared to other diagnostic methods, which may not be suitable for urgent clinical cases.
- Sample Contamination: Contamination of samples during handling or library preparation can lead to incorrect results and necessitate rigorous quality control measures.
- Initial Setup Costs: While the per-base sequencing cost has decreased, the initial setup costs for acquiring NGS instruments and infrastructure can be substantial.
NGS Technologies:
Next-Generation Sequencing (NGS) encompasses a variety of sequencing technologies, each with its unique approach to DNA or RNA sequencing. Here is a list of some prominent NGS technologies:
- Illumina Sequencing:
- Principle: Sequencing by synthesis using reversible terminators.
- Key Features: High accuracy, short read lengths, high throughput, and cost-effectiveness.
- Applications: Whole genome sequencing, exome sequencing, RNA-Seq, and more.
- Ion Torrent Sequencing:
- Principle: Detection of hydrogen ions released during DNA synthesis.
- Key Features: Speed, suitability for targeted sequencing, and benchtop instruments.
- Applications: Targeted sequencing, including cancer panels and amplicon sequencing.
- PacBio Sequencing (SMRT Sequencing):
- Principle: Real-time observation of DNA polymerase during synthesis.
- Key Features: Long read lengths, capability to capture structural variations.
- Applications: De novo genome assembly, full-length RNA sequencing, and epigenetics studies.
- Oxford Nanopore Sequencing:
- Principle: Detection of changes in electrical current as DNA passes through nanopores.
- Key Features: Extremely long read lengths, portable sequencers.
- Applications: Genome sequencing, metagenomics, real-time pathogen detection.
- 454 Pyrosequencing (Roche 454 Sequencing):
- Principle: Detection of light emitted during nucleotide incorporation.
- Key Features: Longer read lengths compared to Illumina.
- Applications: De novo genome sequencing, amplicon sequencing.
- SOLID Sequencing (Sequencing by Oligonucleotide Ligation and Detection):
- Principle: Ligation-based sequencing with fluorescently labeled probes.
- Key Features: High accuracy, suitable for SNP detection.
- Applications: Whole exome sequencing, ChIP-Seq.
- Helicos Sequencing (Single-Molecule Sequencing):
- Principle: Serial imaging of fluorescently labeled nucleotides during synthesis.
- Key Features: Single-molecule sequencing, no amplification bias.
- Applications: Gene expression analysis, RNA-Seq.
- Complete Genomics Sequencing:
- Principle: Direct sequencing of DNA nanoarrays.
- Key Features: No need for library preparation, cost-effective for large projects.
- Applications: Genome sequencing for population studies.
- BGISEQ Sequencing:
- Principle: DNBSEQ technology using combinatorial probe-anchor synthesis.
- Key Features: High throughput, relatively low cost.
- Applications: Genome sequencing, transcriptome analysis.
- Nanopore Arrays (Emerging Technology):
- Principle: Nanopore-based sequencing with improved accuracy and throughput (under development).
Future Scope of NGS technology:
The future of Next-Generation Sequencing (NGS) technology holds exciting possibilities for advancing scientific research, clinical applications, and personalized medicine. Here is a list of the future scope and potential developments in NGS:
- Longer Read Lengths: Continued efforts to increase read lengths will enable more comprehensive genome assembly, better detection of structural variations, and improved characterization of complex regions.
- Single-Molecule Sequencing: Advancements in single-molecule sequencing technologies, such as Oxford Nanopore, may provide ultra-long reads and real-time sequencing, revolutionizing genomics and metagenomics research.
- High-Throughput Platforms: The development of high-throughput NGS platforms will enable faster and more cost-effective sequencing, making large-scale genomic projects more accessible.
- Clinical Diagnostics: NGS will play an increasingly significant role in clinical diagnostics, including the identification of rare genetic disorders, monitoring cancer mutations, and guiding personalized treatment plans.
- Epigenomics and Epitranscriptomics: NGS will continue to unravel the complexities of epigenetic modifications and RNA modifications, shedding light on gene regulation and disease mechanisms.
- Single-Cell Sequencing: Further refinement of single-cell sequencing techniques will provide insights into cellular heterogeneity, developmental biology, and disease processes at the individual cell level.
- Metagenomics and Microbiome Research: Advancements in metagenomic analysis will improve our understanding of microbial communities in various environments, leading to applications in health, agriculture, and environmental sciences.
- Structural Variation Detection: Enhanced methods for accurately detecting and characterizing structural variations will have implications for understanding genetic diseases and their underlying mechanisms.
- Functional Genomics: Integrating NGS with functional genomics techniques will enable researchers to decipher gene function and regulatory networks with higher precision.
- Data Analysis and Interpretation: Continued development of bioinformatics tools and AI-driven approaches will facilitate the analysis and interpretation of complex NGS datasets, making it more accessible to researchers.
- Global Genomic Initiatives: Expanding global genomic initiatives will involve large-scale population sequencing projects to understand genetic diversity, ancestry, and disease susceptibility on a global scale.
- Point-of-Care Sequencing: Portable and miniaturized NGS devices for point-of-care applications, such as rapid pathogen detection, may become more widespread.
- Ethical and Regulatory Frameworks: As NGS continues to generate vast amounts of genetic data, the development of robust ethical guidelines and regulatory frameworks for data privacy and security will be essential.
- Environmental Genomics: NGS will be instrumental in monitoring and managing ecosystems and biodiversity, helping with conservation efforts and ecological research.
- Therapeutic Insights: NGS will contribute to personalized medicine by identifying drug targets, optimizing treatment strategies, and predicting individual responses to therapies.
- Emerging Sequencing Technologies: Novel sequencing technologies currently in development may bring unforeseen advancements and capabilities to genomics research.
Future Advancements and Directions:
- Precision Medicine: Personalized treatment plans based on an individual’s genomic, transcriptomic, and proteomic data will become more common, improving healthcare outcomes.
- Functional Genomics: Advancements in functional genomics, including CRISPR-based gene editing and high-throughput screening, will enable a deeper understanding of gene function and regulation.
- Epigenomics and Epitranscriptomics: Further exploration of epigenetic modifications and RNA modifications will provide insights into gene regulation, development, and disease.
- Single-Cell Omics: Single-cell genomics, transcriptomics, and proteomics will reveal cellular heterogeneity and help understand complex biological processes.
- Multi-Omics Integration: Integrating genomics, transcriptomics, proteomics, and metabolomics data will provide a holistic view of biological systems and disease mechanisms.
- Artificial Intelligence (AI) and Machine Learning: AI-driven data analysis, predictive modeling, and drug discovery will accelerate genomics research and enable data-driven healthcare.
- Metagenomics and Microbiome Research: Continued study of the human microbiome and environmental metagenomics will impact health, agriculture, and ecological research.
- Long-Read Sequencing: Advancements in long-read sequencing technologies will improve genome assembly, structural variation detection, and the study of complex genomic regions.
- Nanopore Sequencing: Further developments in nanopore sequencing will lead to ultra-long reads, real-time sequencing, and portable devices with broader applications.
- Single-Molecule Sequencing: Refinement of single-molecule sequencing techniques will provide unprecedented insights into genomics and molecular biology.
- Drug Discovery and Development: Genomics will play a pivotal role in identifying new drug targets, optimizing drug development, and predicting patient responses to treatments.
- Cancer Genomics: Continued research into cancer genomics will lead to better diagnostics, targeted therapies, and early detection methods.
- Neurogenomics: Genomics will contribute to unraveling the genetic basis of neurological disorders and neurodegenerative diseases, paving the way for potential treatments.
- Environmental Genomics: Genomics will be crucial for monitoring and managing ecosystems, conserving biodiversity, and addressing environmental challenges.
- Global Genomic Initiatives: Large-scale population genomics projects will provide insights into genetic diversity, ancestry, and disease susceptibility on a global scale.
- Ethical and Regulatory Frameworks: Development of robust ethical guidelines and regulations for genomic data privacy, security, and responsible research conduct will remain essential.
- Point-of-Care Genomics: Portable genomics devices for point-of-care applications, such as rapid pathogen detection and disease diagnosis, will continue to evolve.
- Education and Genomic Literacy: Genomic education and public genomic literacy initiatives will help individuals make informed decisions about their health and genetics.
FAQs:
1. What is genomics?
- Genomics is the study of an organism’s complete set of DNA, including all of its genes and non-coding sequences, and how they function and interact.
2. What is Next-Generation Sequencing (NGS)?
- NGS is a high-throughput DNA or RNA sequencing technology that allows for the rapid and cost-effective analysis of entire genomes, transcriptomes, and more.
3. How does NGS work?
- NGS works by breaking DNA or RNA into small fragments, sequencing them, and then reconstructing the original sequence based on the order of nucleotides.
4. What are the main applications of NGS?
- NGS is used for genome sequencing, gene expression analysis, variant discovery, metagenomics, epigenomics, and more in fields like genetics, medicine, and biology.
5. What are genetic variants?
- Genetic variants are differences or mutations in the DNA sequence that can be responsible for variations in traits, diseases, and genetic diversity among individuals.
6. What is personalized medicine?
- Personalized medicine is an approach to healthcare that uses an individual’s genetic information to tailor medical treatments, therapies, and interventions to their unique genetic makeup.
7. What are the limitations of NGS?
- Limitations of NGS include short read lengths, potential sequencing errors, coverage variations, data complexity, and the need for advanced bioinformatics analysis.
8. How is NGS used in clinical diagnostics?
- NGS is used in clinical diagnostics for identifying genetic disorders, detecting cancer mutations, and guiding treatment decisions through precision medicine.
9. What are the ethical considerations in genomics research?
- Ethical considerations in genomics research include issues related to data privacy, informed consent, data sharing, and potential misuse of genetic information.
10. What are some emerging trends in genomics and NGS?
- Emerging trends include single-cell genomics, multi-omics integration, long-read sequencing, AI-driven analysis, environmental genomics, and more.
11. How can I learn more about genomics and NGS?
- You can learn more about genomics and NGS through online courses, textbooks, academic institutions, and genomics research organizations.
12. What are some notable genomics projects worldwide?
- Notable genomics projects include the Human Genome Project, the 1000 Genomes Project, the Cancer Genome Atlas (TCGA), and various population genomics initiatives.
Conclusion:
In conclusion, Next-Generation Sequencing (NGS) has revolutionized genomics and scientific research, offering unprecedented capabilities to decipher the complexities of DNA and RNA at an unprecedented scale and speed. NGS has found applications across a wide spectrum of disciplines, from unraveling the genetic underpinnings of diseases to advancing our understanding of the environment and biodiversity. Its potential for personalized medicine and its role in driving innovation in fields like oncology, microbiology, and agriculture underscore its profound impact on our quest to unlock the mysteries of life. As NGS technologies continue to evolve and become more accessible, the future promises even greater breakthroughs, paving the way for transformative discoveries and improved healthcare outcomes.
However, it is essential to recognize the ethical and privacy challenges posed by NGS, requiring careful consideration of data handling, consent, and regulations. As we embark on this genomic journey, it is crucial to balance the immense opportunities NGS offers with the responsibilities it entails, ensuring that the benefits of genomics are realized for the betterment of society while respecting individual rights and ethical principles.
Next-Generation Sequencing Key Terms and Abbreviations:
| DNA | Deoxyribonucleic acid |
| RNA | Ribonucleic acid |
| tRNA | Transfer ribonucleic acid |
| NGS | Next-generation sequencing |
| PCR | Polymerase chain reaction |
| cDNA | Complementary DNA |
| gDNA | Genomic DNA |
| RNA-seq | RNA-sequencing |
| SMS | Single molecule sequencing |
| SBS | Sequencing by synthesis |
| WGS | Whole genome sequencing |
| WES | Whole exome sequencing |
| WGBS | Whole genome bisulfate sequencing |
| ChIP-seq | Chromatin immunoprecipitation sequencing |
| MeDIP-seq | Methylation dependent immunoprecipitation followed by sequencing |
| P5 | Primer 5 (sequencing adapter) |
| P7 | Primer 7 (sequencing adapter) |
| 3G | Third-generation sequencing |
| 4G | Fourth-generation sequencing |
| dNTPs | Deoxynucleoside triphosphate |
| FastQC | Fast quality control |
| Flow cell | Glass slide containing fluidic channels |
| Library | Pool of DNA fragments with adapters attached |
| Indel | Insertion or deletion of bases |
| Adapters | Platform-specific sequences for fragment recognition |
| fastp | Fast preprocessor |
| De novo sequencing | Novel genome sequencing in the absence of a reference sequence |
| Contigs | From “contiguous” – overlapping DNA fragments |
| SNP | Single nucleotide polymorphism |
| Scaffold | Created by linking contigs together using additional information |
| SBL | Sequencing by ligation |
| Paired-end | Reading a sequencing fragment from both ends and linking the data |
| Mate pair | Linking sequencing reads separated by an intervening DNA region |